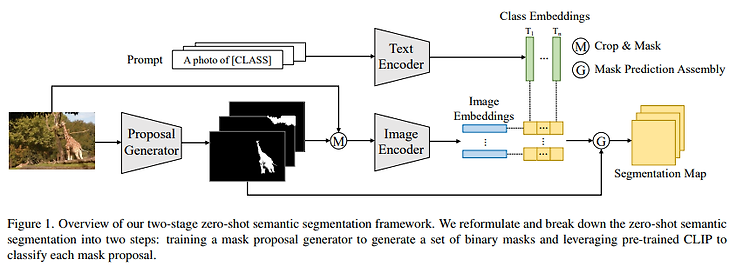
A Simple Baseline for Zero-Shot Semantic Segmentation with Pre-trained Vision-language Model https://arxiv.org/pdf/2112.14757.pdf CLIP을 zero-shot semantic segmentation에 적용한 논문. MaskFormer로 binary mask를 생성하고 생성한 mask에 대해 mask classification으로 prediction을 수행한다. classifier의 weight를 CLIP의 pre-trained text representation로 사용. 따라서 unseen으로 zero-shot이 가능하다.