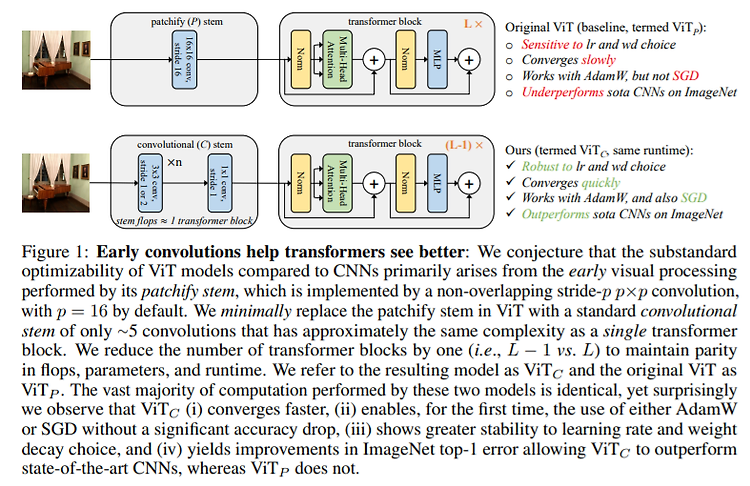
LiT: Zero-Shot Transfer with Locked-image Text Tuning PDF, Zero-Shot Transfer, Zhai et al, arXiv 2021 Summary Transfer Learning과 Zero-Shot Transfer 의 차이점 먼저 설명하고 논문을 소개하겠다. Transfer Learning은 big dataset로 pre trained된 big model을 down stream으로 fine-tuning을 하는 것이다. 즉, 두 가지 철차로 이루어진다. (1) pre-training, (2) fine-tuning. 이 과정을 통하여 데이터가 적은 task에서도 좋은 성능을 가진 모델을 사용할 수 있다. Zero-Shot Transfer은 fine-tunin..