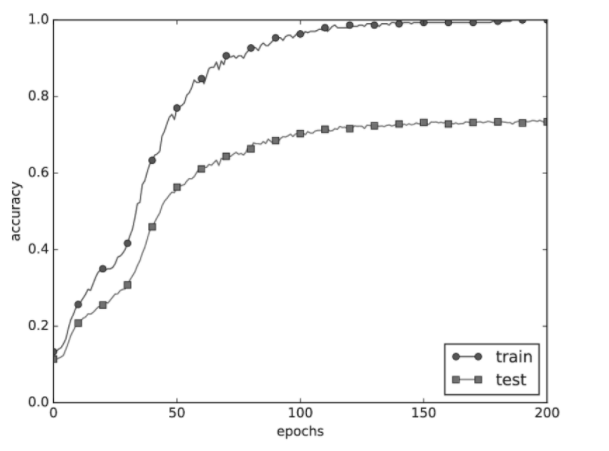
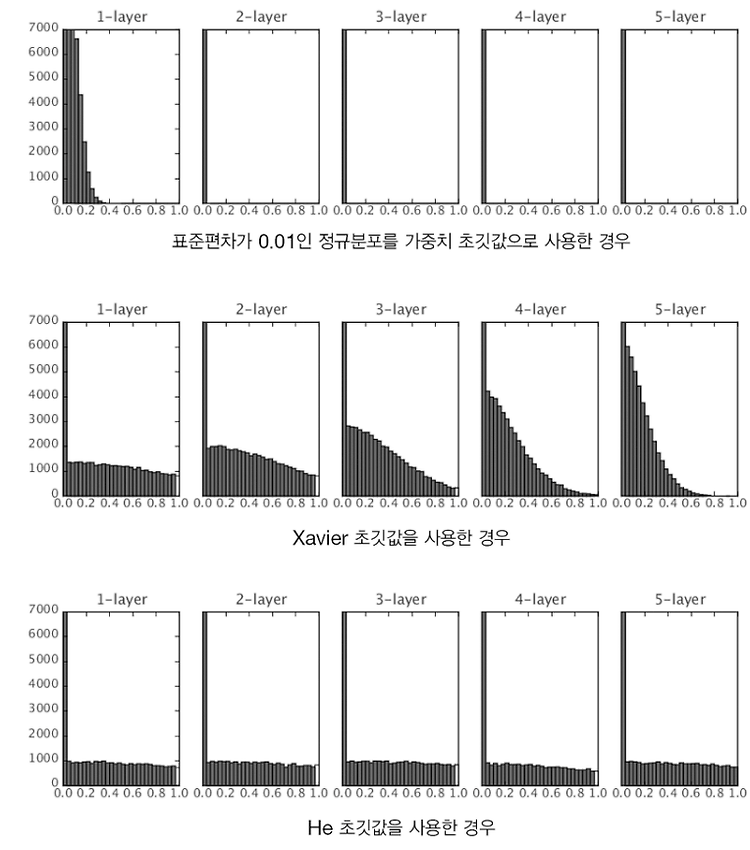
사이토고키의 을 공부하고 정리해보았습니다. [딥러닝] 검증 데이터 - 하이퍼파라미터의 성능을 평가 사이토고키의 을 공부하고 정리해보았습니다. 적절한 하이퍼파라미터 값 찾기 신경망에는 하이퍼파라미터가 다수 등장합니다. 여기서 말하는 하이퍼파라미터� deep-learning-study.tistory.com 검증 데이터로 하이퍼파라미터의 성능을 평가한다는 것을 배웠습니다. 이번에는 하이퍼파라미터 최적화를 알아보겠습니다. 하이퍼파라미터 최적화 하이퍼파라미터를 최적화할 때의 핵심은 하이퍼파라미터의 '최적 값'이 존재하는 범위를 조금씩 줄여간다는 것입니다. 범위를 조금씩 줄이려면 우선 대략적인 범위를 설정하고 그 범위에서 무작위로 하이퍼파라미터 값을 골라낸 후, 그 값으로 정확도를 평가합니다. 정확도를 잘 살피면서..