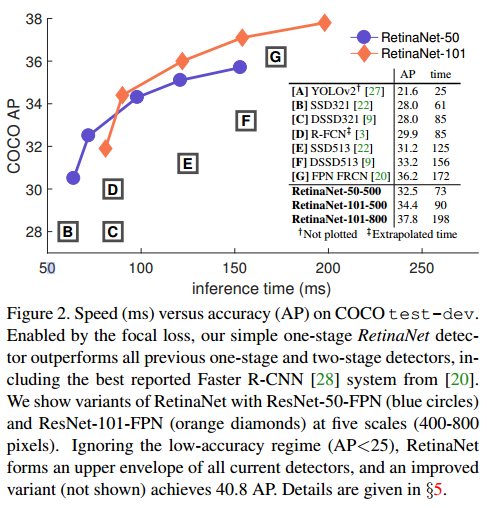
RetinaNet 논문은 모델이 예측하기 어려운 hard example에 집중하도록 하는 Focal Loss를 제안합니다. ResNet과 FPN을 활용하여 구축된 one-stage 모델인 RetinaNet은 focal loss를 사용하여 two-stage 모델 Faster R-CNN의 정확도를 능가했습니다. 클래스 불균형 문제(Class imbalance proplem) R-CNN과 같은 two-stage detector이 one-stage detector보다 높은 정확도를 나타내는 것은 일반적입니다. 하지만 one-stage detector(YOLO, SSD)는 속도가 빠르다는 장점이 있습니다. RetinaNet 저자는 one-stage detector의 낮은 정확도의 원인은 객체와 배경 클래스 불균형..