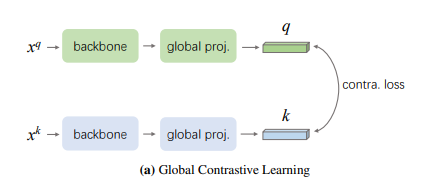
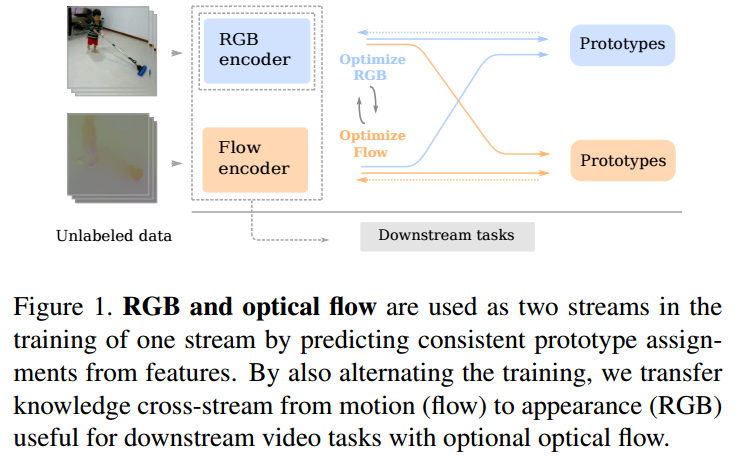
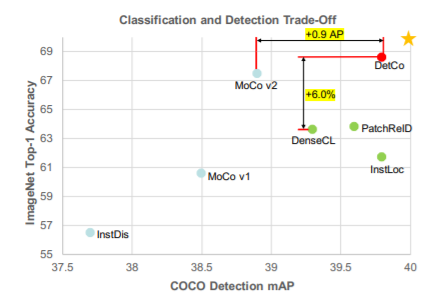
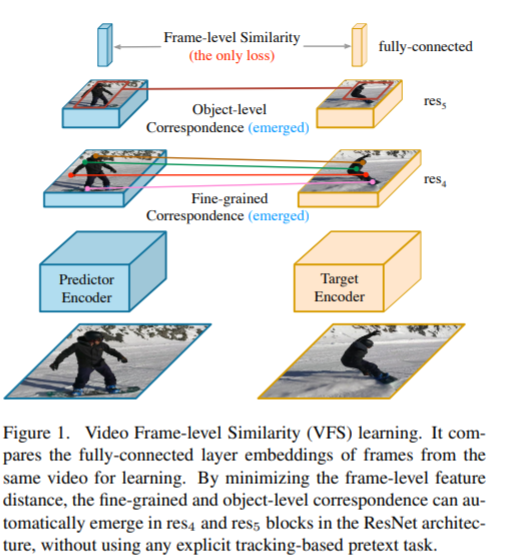
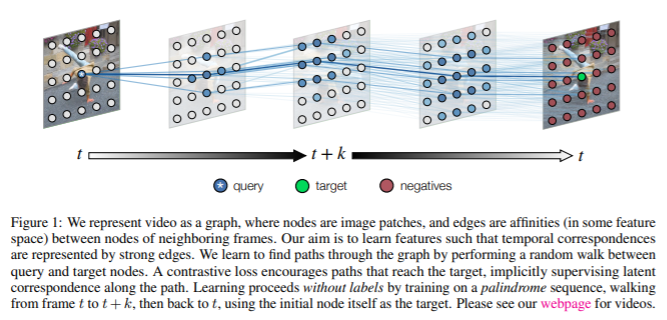
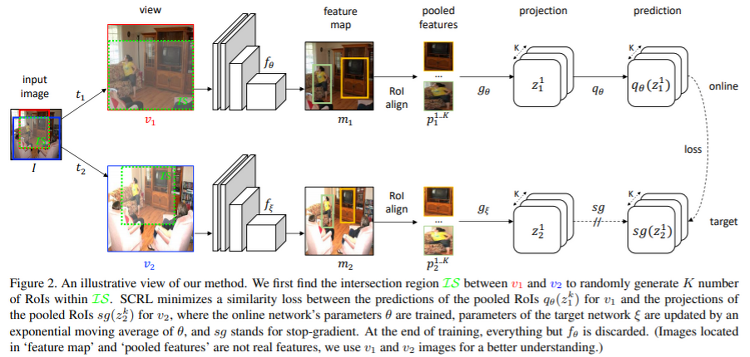
심심해서 적어보는 글. Self-supervised learning은 데이터가 부족한 환경에서 사용하는 것이 아니라, 데이터는 많은데 annotation이 없는 경우에 사용하는 것이다. unlabeled data 로부터 어떻게 pretask를 만들어서 효율적인 representation을 뽑아내느냐가 중요하며, 작년 까지 핫했던 SSL 모델들(DINO, MoCO, SimCL?)은 unlabeled data에 aumentation에 강하게 줘서 contrastive learning으로 augmentation에 불변한 representation을 뽑아내는 방향으로 발전해왔다. 22년 SSL 논문은 안읽어봐서 모르겠는데 현재도 비슷한 방향으로 연구가 진행되고 있지 않을까 싶다. 또한 SSL방법론이 성능을 내기..