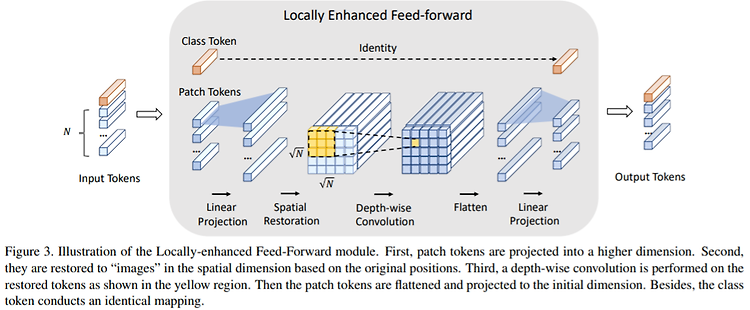
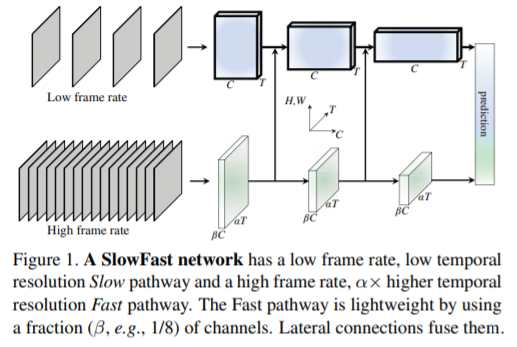
Incorporating Convolution Designs into Visual Transformers Kun Yuan, Shaopeng Guo, Ziwei Liu, Aojun Zhou Fengwei Yu, Wei Wu, arXiv 2021 PDF, Transformer By SeonghoonYu August 5th, 2021 Summary CeiT is architecture that combines the advantages of CNNs in extracting low-level features, strengthening locality, and the advantages of Transformers in establishing long-range dependencies. ViT has two p..