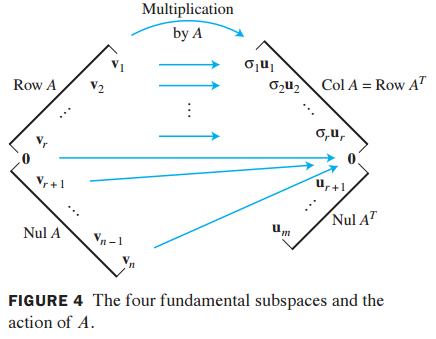
Mathematics for Machine Learning를 공부하고 정리한 포스팅입니다. 2.3 연립 방정식의 해(Solving Systems of Linear Equations) 다음과 같은 연립 방정식이 있습니다. $a_{ij}$는 실수, $b_i$는 상수, $x_j$는 미지수 입니다. 위 연립 방정식은 Ax=b로 간단히 표현할 수 있습니다. 이제 행렬 곱셈, 덧셈 과 같은 행렬 연산을 정의하고 위와 같은 연립 방정식을 푸는 방법과 역행렬을 찾는 방법을 알아보겠습니다. 2.3.1 특수해와 일반해(Particular and General Solution) 아래와 같은 연립 방정식을 어떻게 푸는지 알아보겠습니다. 2개의 방정식과 4개의 미지수로 이루어진 연립 방정식입니다. 방정식의 개수보다 미지수의 개..